
 English
English99941
 About the author Li Haoyu: Currently a second-year doctoral student in the Department of Computer Science at Columbia University, USA, he is conducting research on storage systems under the guidance of his supervisor, Professor Asaf Cidon. Prior to this, Li Haoyu obtained his undergraduate and master's degrees from Shanghai Jiao Tong University, and conducted research on Java virtual machine memory management at the Institute of Parallel and Distributed Systems (IPADS). Zhao Jiawei: A front-line coder who works as a storage R&D engineer in a server company. He likes to study storage-related technologies and basic kernel principles every day. This article is based on the content of Dr. Li Haoyu’s live broadcast. Thank you to Jia Wei for organizing the content of this live broadcast. 1.Background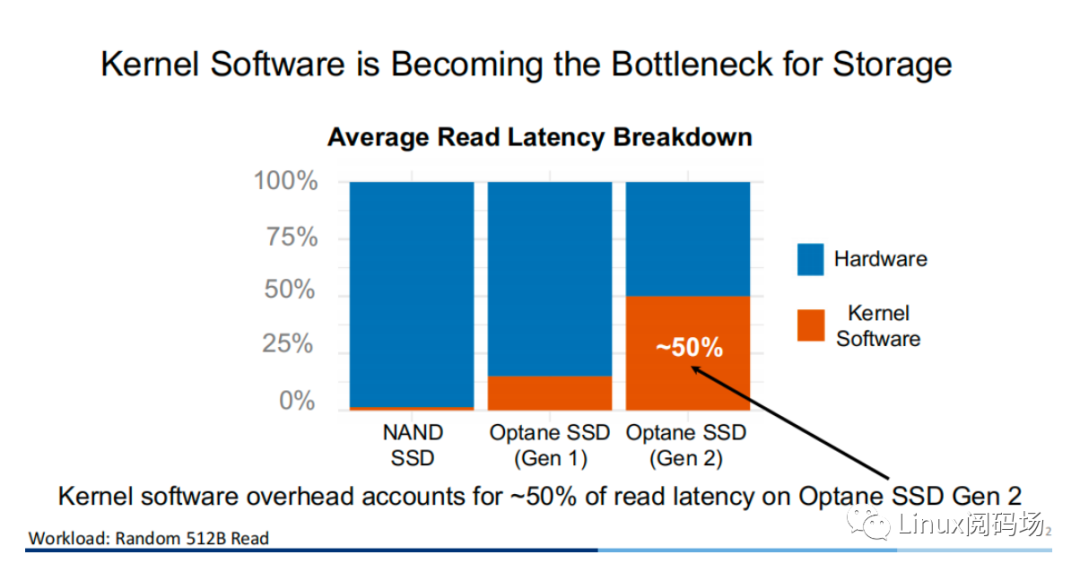 With the upgrade and development of storage devices, the performance of contemporary storage devices is getting higher and higher, and the latency is getting lower and lower. For the kernel, the performance overhead caused by the software of the Linux I/O storage stack cannot be ignored. Also under 512B random read conditions, in the test example using the second-generation Optane SSD as the storage device, the performance overhead caused by the kernel software (Linux storage stack) has reached as high as 50%. 2. Traditional Ways vs. XRP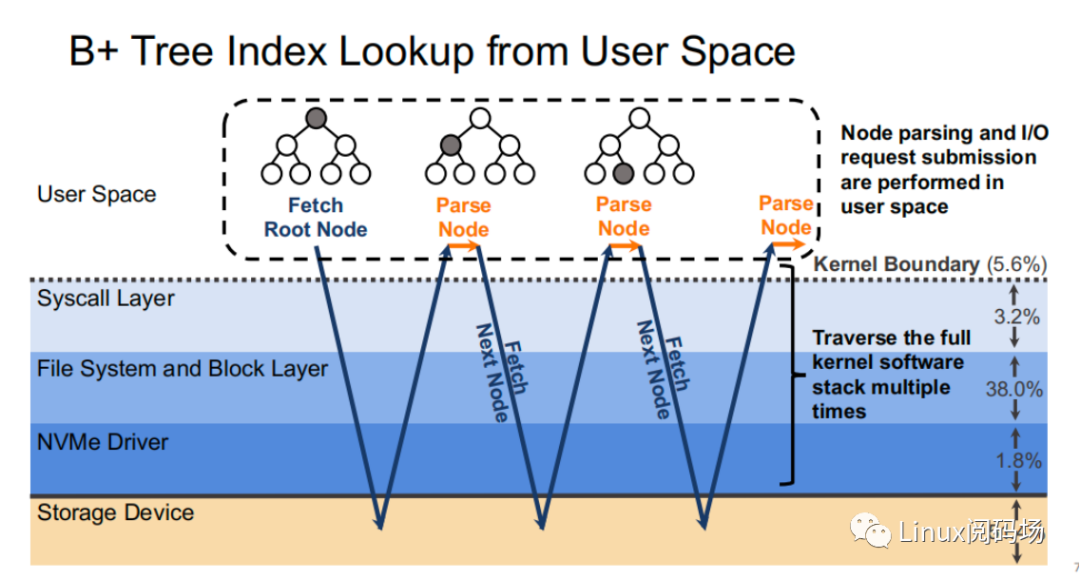 Let's look at a practical example. Suppose there is a B+ tree with a tree height of 4 stored in the storage device. When we start from the root node, we need to go through a total of three disk accesses to get the final leaf node. The middle index node is meaningless to the user, but it also requires a complete storage stack path. During each disk access process, the storage stack costs 48.6% of the entire storage path. 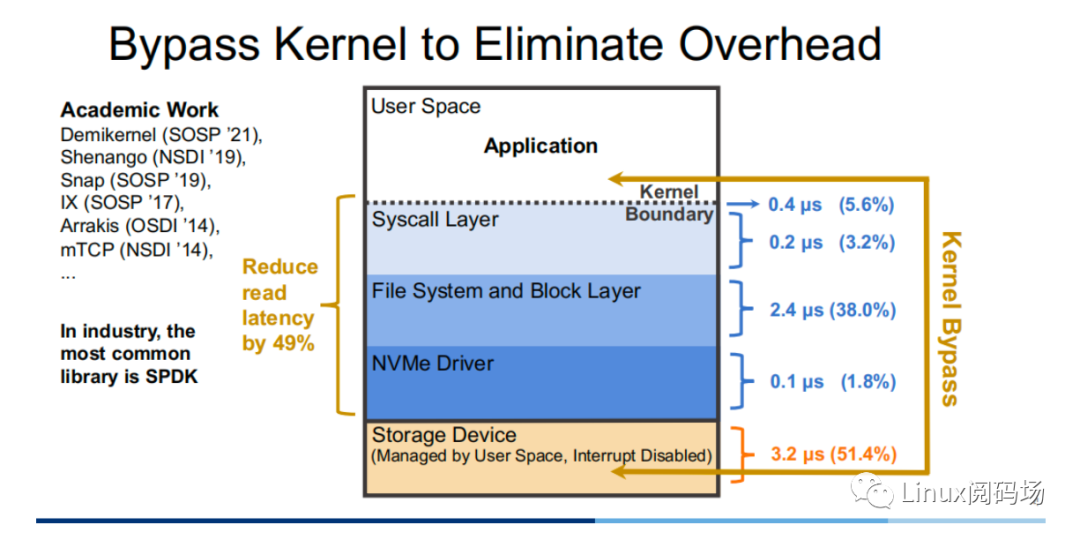 Obviously, redundant storage stack paths restrict the performance of high-performance storage devices, so an intuitive optimization idea is to use Kernel Bypass to bypass the storage stack in the kernel to improve storage performance. Currently, in academia, work in this area includes Demikernel, Shenango, Snap, etc., while the most widely used in the industry is Intel's SPDK. 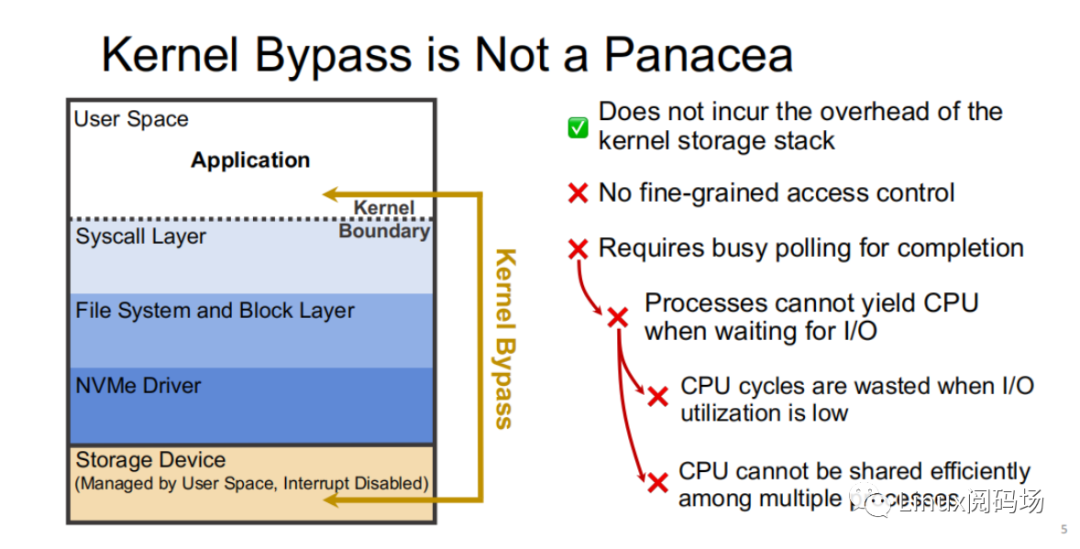 However, Kernel Bypass technology is not a silver bullet. Although it can reduce the overhead of the kernel storage stack, it also has the following shortcomings: 1. No access control with appropriate granularity 2. The polling method needs to be used to determine whether the I/O is completed. This will cause the CPU where the Polling process is located to just idle in most cases when the I/O utilization is low, which wastes CPU cycles. At the same time, the CPU resources cannot be shared efficiently among multiple processes. 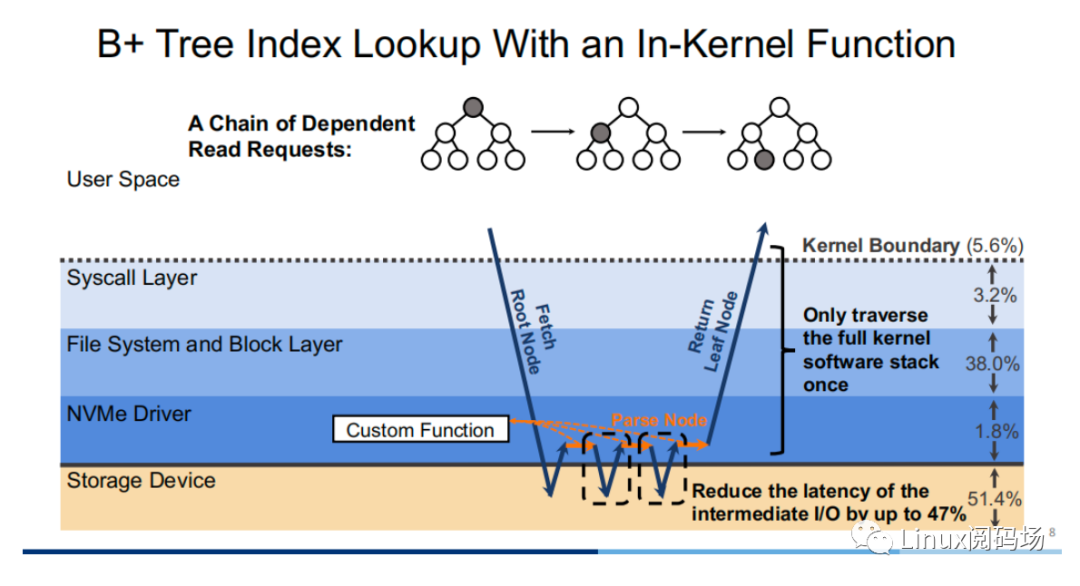 The full name of XRP is eXpress Resubmission Path (fast resubmission path). Unlike SPDK, which completely bypasses the kernel storage stack and uses polling to access storage, XRP achieves acceleration by resubmitting intermediate requests directly in the NVMe driver layer, thereby avoiding the need for intermediate requests to pass through a lengthy storage stack before being submitted. Reflecting on the above example, it can be clearly seen that using the XRP storage access method, only the first request and the last response will go through a complete storage stack path. Obviously, within the allowed range, the higher the B+ tree is, the more obvious the acceleration effect of XRP will be. 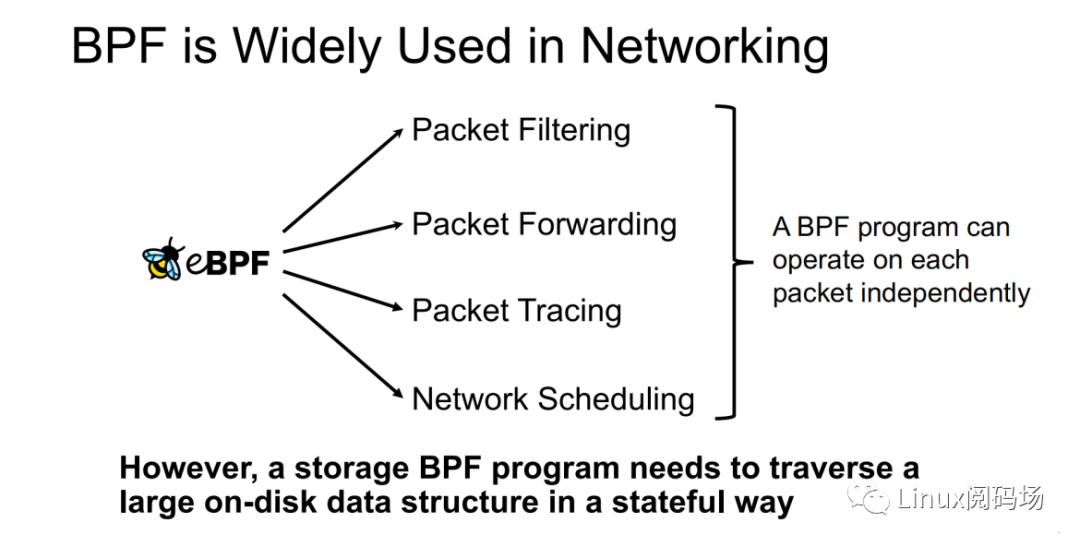 Now that the optimization ideas are in place, how can we resubmit the request to the NVMe driver layer? Here we can learn from the implementation ideas of XDP. XDP uses eBPF to implement independent operations on each packet (packet filtering, packet forwarding, packet tracking, network scheduling). XRP can also be implemented through the BPF program. 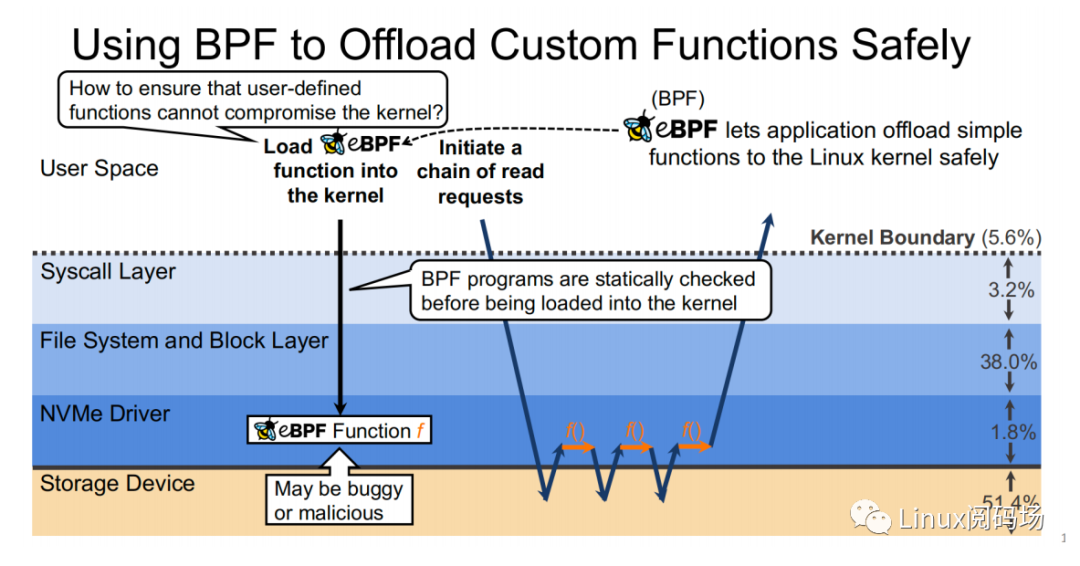  XRP is the first system to use eBPF to reduce kernel storage software overhead. The main challenges it faces are: 1. How to implement file offset translation in the NVMe driver layer 2. How to enhance eBPF verifier to support storage application scenarios 3. How to resubmit NVMe request 4. How to interact with application layer Cache  XRP introduces a new BPF type (BPF_PROG_TYPE_XRP), which contains 5 fields, namely 1. char* data: a buffer used to buffer data read from disk 2. int done: Boolean semantics, indicating whether the resubmission logic should be returned to the user or should continue to resubmit I/O requests 3. uint64_t next_addr[16]: logical address array, which stores the logical address of the next resubmission 4. uint64_t size[16]: stores the size of the next resubmission request. 5. char* scratch: private space of user and BPF function, used to pass parameters from user to BPF function. BPF functions can also use this section space to store intermediate data. For simplicity, the default scratch size is 4KB. At the same time, in order to avoid BPF Verifier verification failure due to infinite loops, the maximum number of fanouts of the B+ tree is specified in the code. MAX_FANOUT, its value is 16. 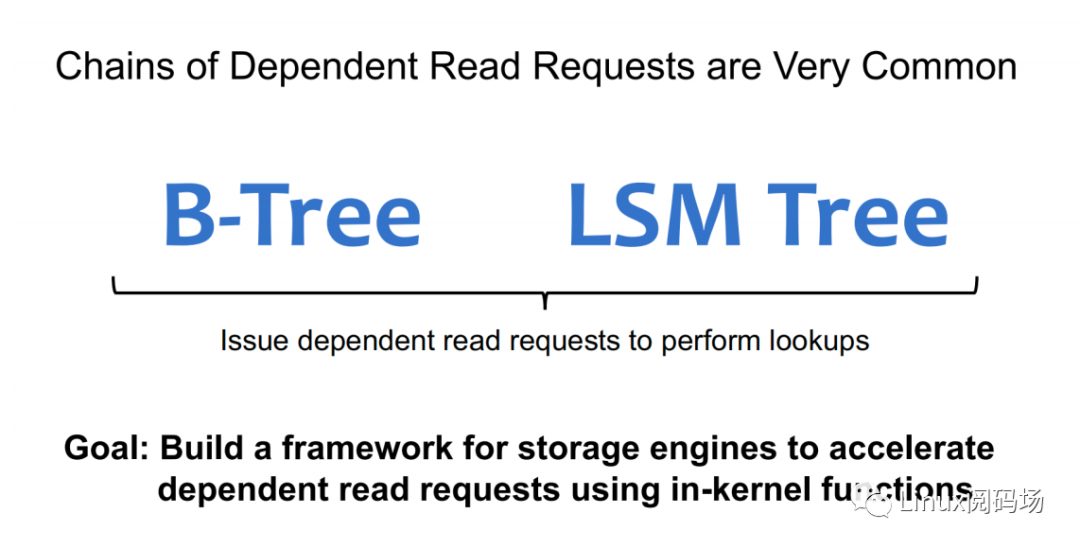  Currently, the most common chained read requests are B-Tree and LSM Tree, and XRP inherits BPF-KV (a simple B+ Tree-based key-value storage engine) and WIREDTIGER (mongoDB's back-end key-value storage engine) respectively. 3. Experimental testing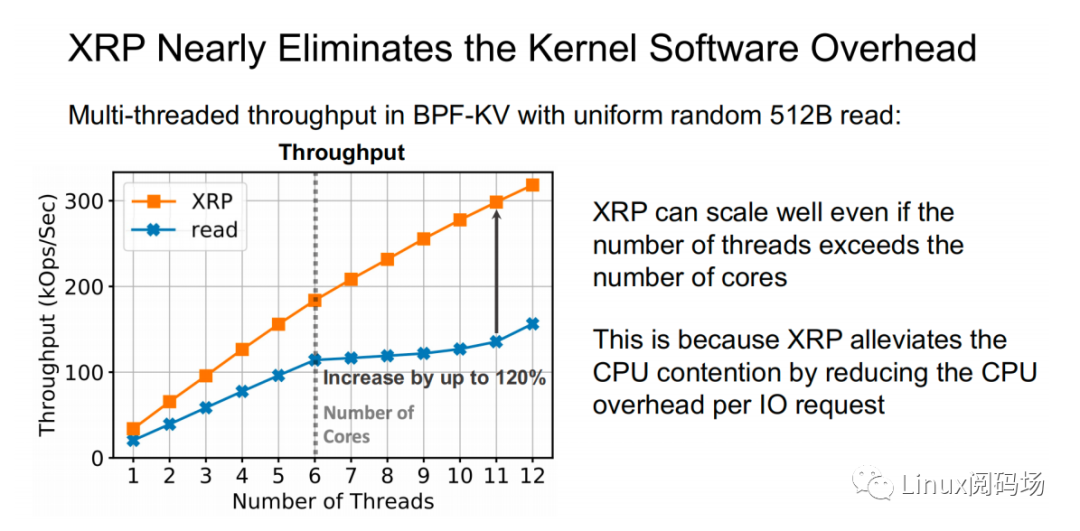 The picture above shows the performance comparison test between standard read and XRP in the 512B random read test. It can be seen that as the number of threads increases, XRP's throughput maintains a linear growth trend. At the same time, XRP alleviates the CPU contention problem by reducing the CPU overhead for each I/O request. 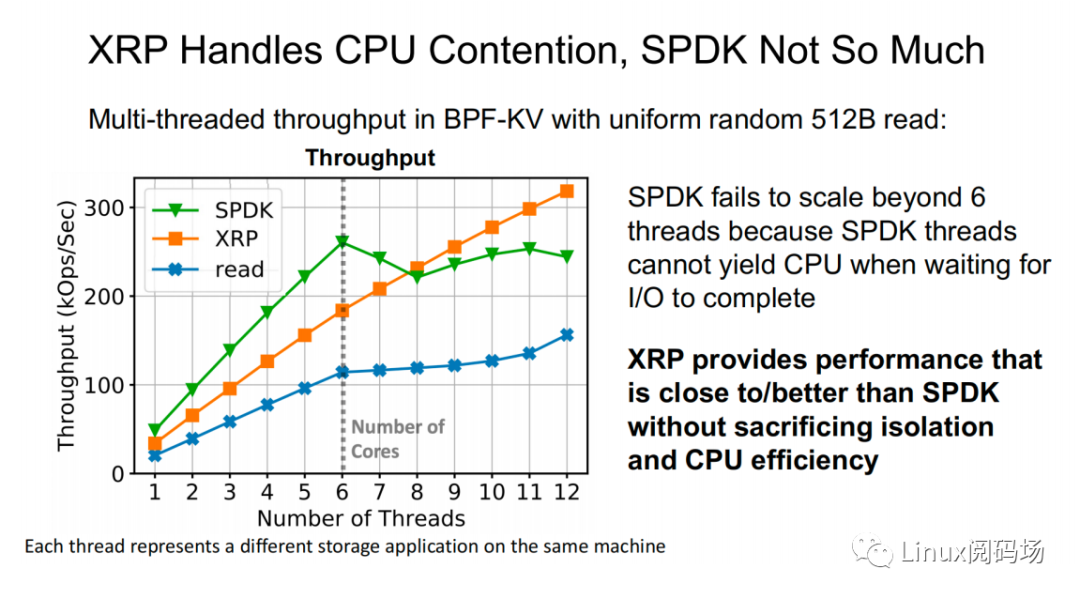 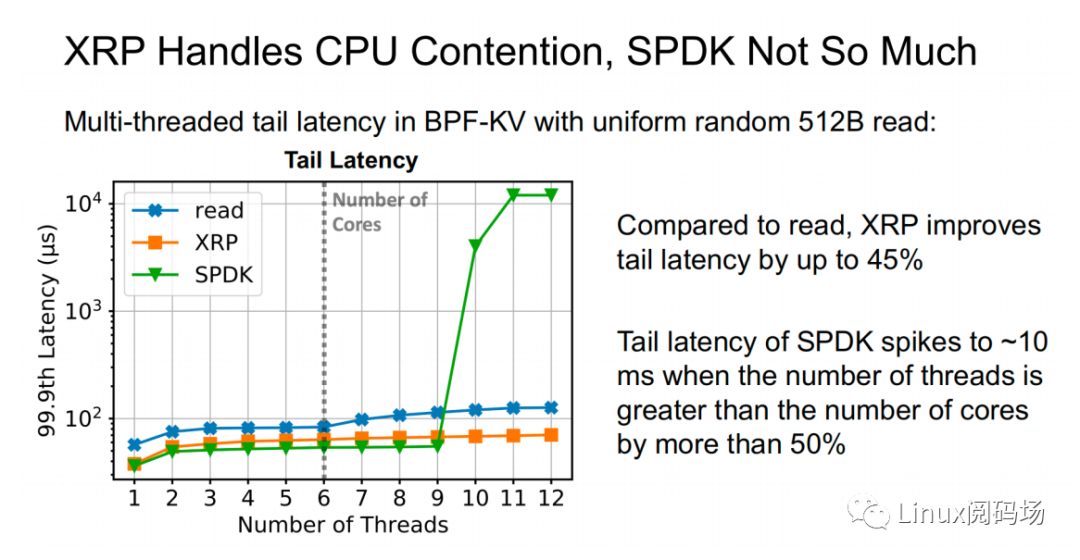 The two figures above also show the comparison of throughput and tail latency between standard read, XRP and SPDK in the 512B random read test (CPU core number is 6). When the number of threads is less than or equal to the number of CPU cores, the performance changes of the three are stable, and the order from high to low is SPDK > XRP > read. When the number of threads exceeds the number of cores, SPDK performance begins to decline severely, and standard read performance declines slightly, while XRP still maintains a stable linear growth. This is mainly because SPDK uses polling to access the completion queue of the storage device. When the number of threads exceeds the number of cores, the competition for the CPU between threads and the lack of synchronization will cause all threads to experience a significant increase in tail latency and a significant decrease in overall throughput. 4. Summary XRP is the first system to apply BPF to accelerate general storage functions. It can enjoy the performance advantages of kernel bypass without sacrificing CPU usage and access control. Currently, the XRP team is still actively integrating XRP with some other popular key-value storage engines, such as RocksDB. Welcome to join the "Storage System Research Discussion" group Please add WeChat: Linuxer2022 Essence articles: [Essence] Summary of original essence articles from Linux Reading Field |

|

|

|

|

|